雲端與地端的架構差異認知不足導致的性能陷阱
前言
許多企業在上雲初期,經常基於成本考量或錯誤認知,將應用程式伺服器(AP)與資料庫(DB)部署在不同區域。這種做法在地端環境中影響較小,但在雲端環境中卻會造成嚴重的性能問題。本文透過台北-東京的實際案例,說明距離對雲端架構的致命影響。
核心問題:
- 地端思維:同個機房內不同區域延遲可忽略
- 雲端現實:跨區域延遲可達數十毫秒
- 結果:連線建立時間從毫秒級暴增到秒級
1. 地端 vs 雲端的延遲差異
1.1 地端環境的延遲特性
傳統地端機房:
同機房不同機櫃:RTT < 1ms
同城市不同機房:RTT < 5ms
同國家不同城市:RTT < 20ms地端架構師的經驗:
- AP和DB分別放在不同機櫃:幾乎無延遲影響
- 災備機房放在不同城市:RTT約10-15ms,可接受
- 習慣性認為「網路延遲不是問題」
1.2 雲端環境的延遲現實
AWS跨區域延遲:
同區域不同AZ:RTT 1-3ms
不同區域 (亞太):RTT 20-100ms
跨大洲區域:RTT 150-300ms案例:台北AP + 東京DB
- 地理距離:2,100公里
- 實測RTT:40-50ms
- 連線建立時間:300ms
1.3 認知落差的根源
地端思維錯誤:
"反正都是網路連線,距離應該沒差多少"
"雲端網路應該比較快才對"
"成本考量優先,性能可以後續調校"雲端現實:
距離 = 延遲 = 性能殺手
物理定律在雲端同樣適用
網路優化無法打破光速限制2. RTT概念與影響
2.1 什麼是RTT
RTT (Round Trip Time):資料封包往返時間
台北AP → 東京DB → 台北AP = 1個RTT
實際測量:
$ ping tokyo-rds-endpoint.amazonaws.com
PING tokyo-rds-endpoint: 45.2ms ← 這就是RTT
PING tokyo-rds-endpoint: 48.1ms
PING tokyo-rds-endpoint: 42.8ms
平均RTT: 45ms2.2 為什麼RTT這麼重要
每次資料庫互動都需要多次RTT:
- 不是「發送查詢→收到結果」這麼簡單
- 需要建立連線、認證、查詢、確認等多個步驟
- 每個步驟都是一次「請求→等待→回應」
地端vs雲端的差異:
地端環境 (RTT 1ms):
連線建立 = 6.5 × 1ms = 6.5ms
雲端跨區 (RTT 45ms):
連線建立 = 6.5 × 45ms = 293ms3. 連線建立的技術細節
3.1 為什麼需要6.5次RTT?
步驟1:TCP三方交握 (1.5 RTT)
台北AP → 東京DB:「我要連線」 (單向 22ms)
東京DB → 台北AP:「好,我準備好了」 (單向 22ms)
台北AP → 東京DB:「確認連線建立」 (單向 22ms)
小計:1.5 × RTT = 68ms步驟2:資料庫協定協商 (2 RTT)
台北AP → 東京DB:「我使用PostgreSQL協定」 (45ms往返)
東京DB → 台北AP:「收到,這是我的參數」 (45ms往返)
小計:2 × RTT = 90ms步驟3:使用者認證 (3 RTT)
東京DB → 台北AP:「請提供認證資訊」 (45ms往返)
台北AP → 東京DB:「這是我的帳號密碼」 (45ms往返)
東京DB → 台北AP:「認證成功,歡迎使用」 (45ms往返)
小計:3 × RTT = 135ms3.2 時間分解表
| 階段 | RTT次數 | 地端時間 (1ms RTT) | 雲端時間 (45ms RTT) | 差異倍數 |
|---|---|---|---|---|
| TCP握手 | 1.5 | 1.5ms | 68ms | 45倍 |
| 協定協商 | 2.0 | 2ms | 90ms | 45倍 |
| 使用者認證 | 3.0 | 3ms | 135ms | 45倍 |
| 總計 | 6.5 | 6.5ms | 293ms | 45倍 |
4. 實際業務影響
4.1 性能衝擊
無連線池情況:
每次查詢 = 連線建立 + 查詢執行 + 連線關閉
= 300ms + 5ms + 22ms
= 327ms
地端同樣操作 = 1ms + 5ms + 0.5ms = 6.5ms
性能下降 = 327ms ÷ 6.5ms = 50倍吞吐量影響:
地端環境:1000ms ÷ 6.5ms ≈ 154 QPS
雲端跨區:1000ms ÷ 327ms ≈ 3 QPS
吞吐量下降 98%4.2 用戶體驗災難
電商網站範例:
商品頁面載入:
- 查詢商品資訊 (327ms)
- 查詢庫存狀態 (327ms)
- 查詢價格資訊 (327ms)
- 查詢用戶評價 (327ms)
總響應時間:1.3秒 vs 地端的26ms
用戶跳出率暴增4.3 常見的錯誤決策
成本導向的錯誤思維:
「東京DB比較便宜,台北AP可以連過去」
「反正都是AWS內網,應該很快」
「先這樣部署,有問題再調整」忽略的隱性成本:
- 開發團隊調校時間
- 用戶體驗下降損失
- 架構重新設計成本
- 業務影響和聲譽損失5. 為什麼很多人踩這個坑?
5.1 地端經驗的誤導
地端架構師常見想法:
✗ 「我以前跨城市部署都沒問題」
✗ 「雲端網路應該比實體線路更快」
✗ 「AWS內部網路延遲應該很低」
✗ 「可以靠調校解決延遲問題」現實情況:
✓ 雲端跨區域 ≠ 地端跨機房
✓ 物理距離決定延遲下限
✓ 協定層級延遲無法消除
✓ 光速就是物理極限5.2 雲端知識的不足
技術認知盲點:
- 不了解雲端區域的實際地理分布
- 不理解RTT對應用程式的放大效應
- 高估了網路優化的能力
- 低估了協定握手的時間成本
決策流程問題:
- 架構設計時只考慮功能需求
- 成本分析忽略性能影響
- 缺乏跨區域部署的性能測試
- 沒有建立延遲監控和告警
6. 光速的物理限制
6.1 無法突破的物理定律
光纖中的光速:
真空光速:300,000 km/s
光纖光速:約200,000 km/s (折射率影響)台北到東京的理論極限:
直線距離:2,100km
理論最小單向時間:2,100km ÷ 200,000km/s = 10.5ms
理論最小RTT:21ms
實際RTT:45ms (包含路由和設備延遲)6.2 技術無法改變的事實
任何優化都無法突破:
- CDN無法加速資料庫連線
- 更快的CPU無法減少傳播延遲
- 更大的頻寬無法縮短距離
- 任何協定優化都受限於物理RTT
7. 正確的雲端架構思維
7.1 距離敏感性認知
高延遲敏感:
- OLTP資料庫操作
- 即時交易系統
- 互動式用戶界面
- 頻繁的API呼叫
相對延遲容忍:
- 批次資料處理
- 報表生成
- 資料同步作業
- 備份和歸檔
7.2 架構設計原則
核心原則:
1. 高頻互動組件必須就近部署
2. AP與DB應在同一區域
3. 跨區域只用於災備和副本
4. 延遲測試應在設計階段進行決策框架:
RTT < 5ms:可忽略延遲影響
RTT 5-20ms:需要評估業務影響
RTT > 20ms:高風險,需要特殊設計
RTT > 50ms:不建議直接連線8. 結論
8.1 核心教訓
地端思維在雲端行不通:
- 雲端的「近」和「遠」差異巨大
- 區域選擇是架構設計的關鍵決策
- 成本優化不應犧牲基本性能
300ms連線時間的真相:
- 這是協定標準和物理定律的必然結果
- 45ms RTT × 6.5次握手 = 293ms
- 任何技術手段都無法根本性改善
8.2 實務建議
架構設計時:
- 優先考慮AP與DB的部署距離
- 進行跨區域性能測試
- 建立延遲監控機制
- 準備回滾和遷移計劃
避免常見錯誤:
- 不要用地端經驗指導雲端架構
- 不要低估距離對性能的影響
- 不要期望透過調校解決根本問題
- 不要忽視用戶體驗的重要性
8.3 最終要點
雲端架構的成功關鍵不在於技術複雜度,而在於理解和尊重物理定律。當我們把AP放在台北、DB放在東京時,我們實際上是在與光速作對—這場戰爭我們註定會敗。
記住:在雲端世界中,距離不僅僅是數字,它是性能的敵人。


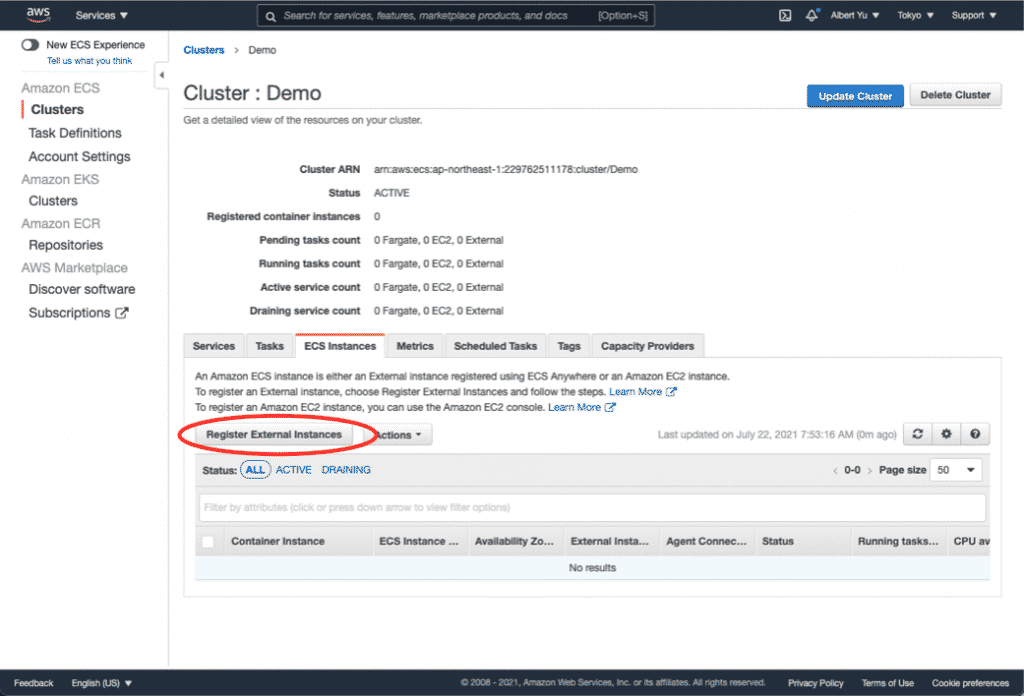
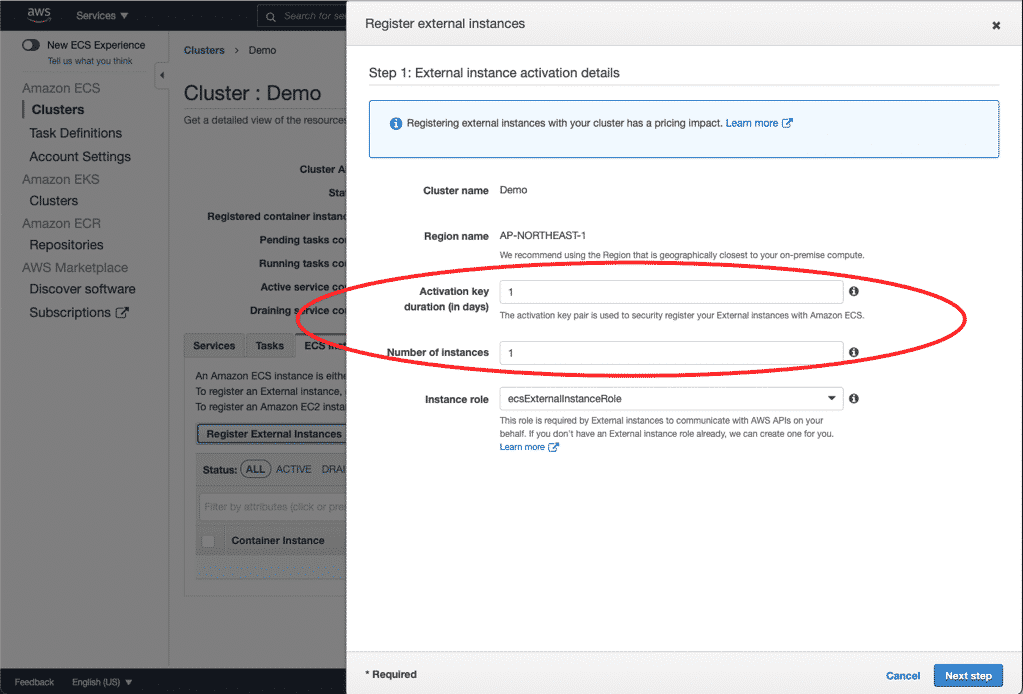
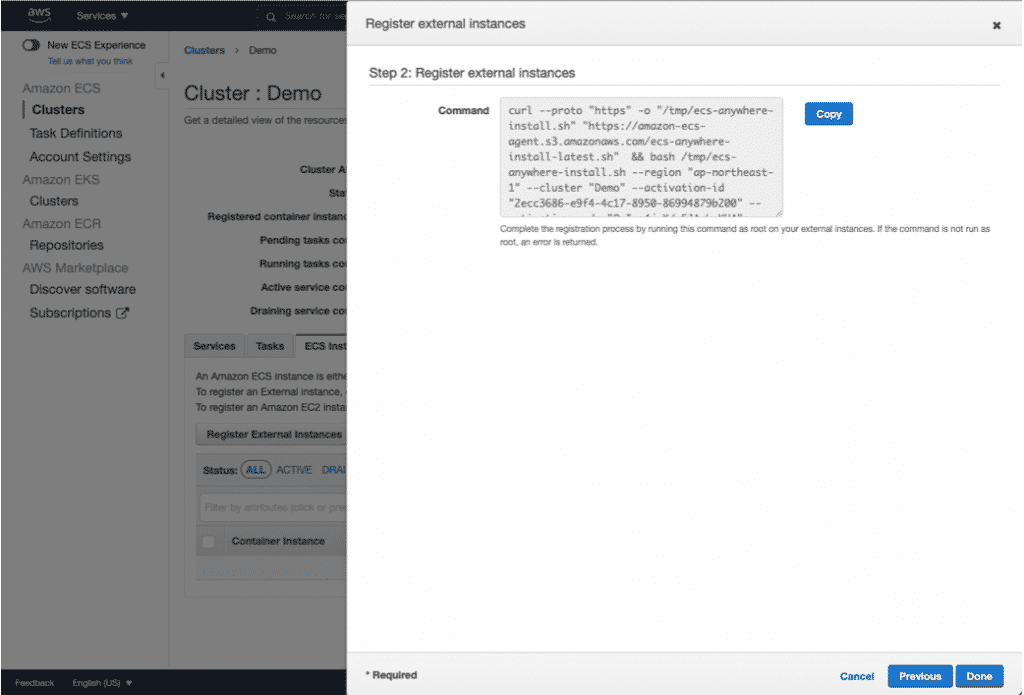



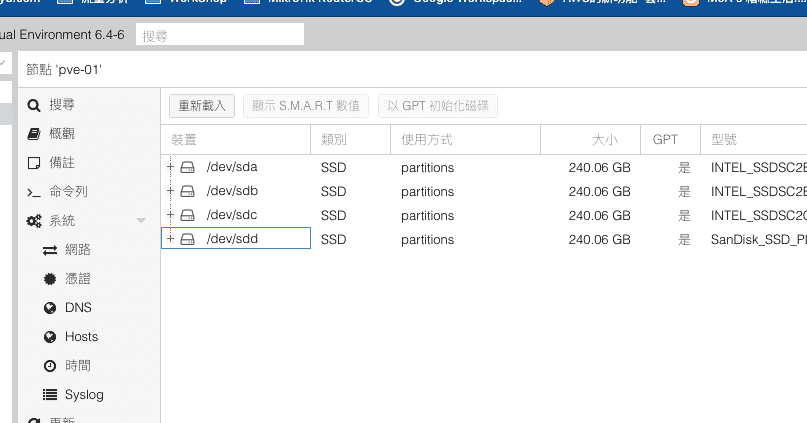
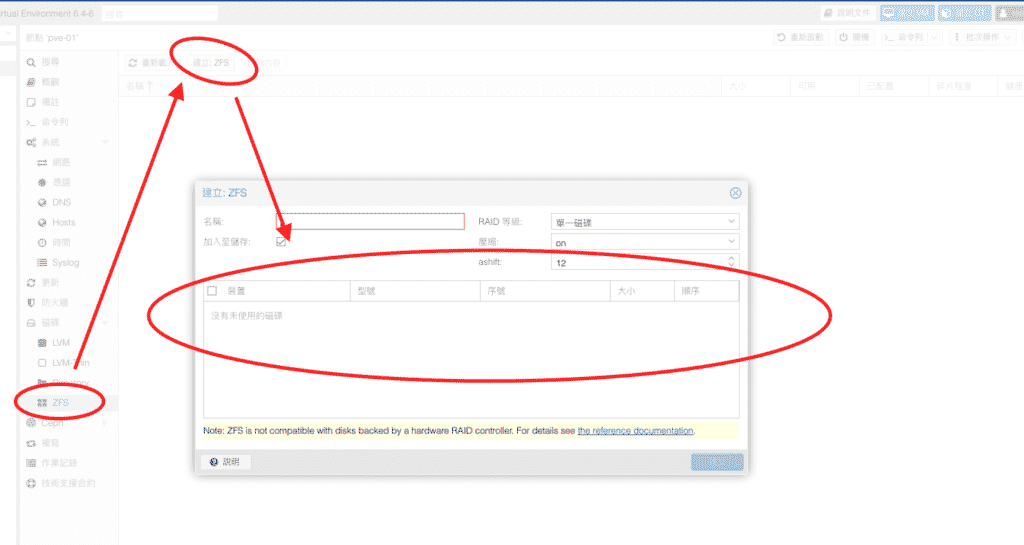
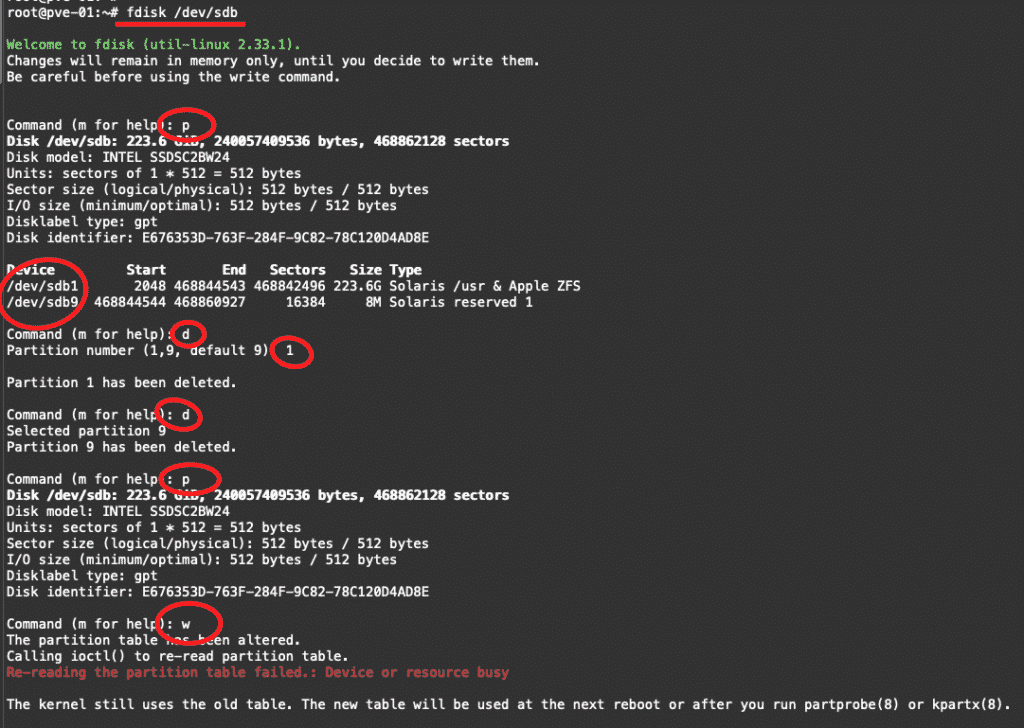
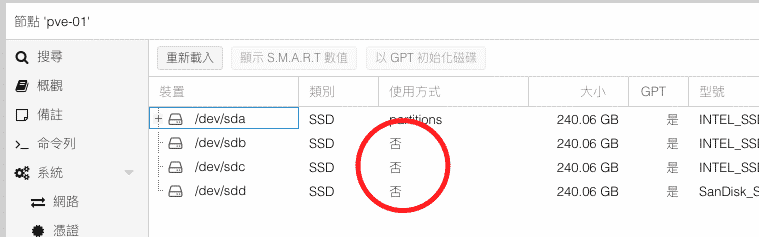
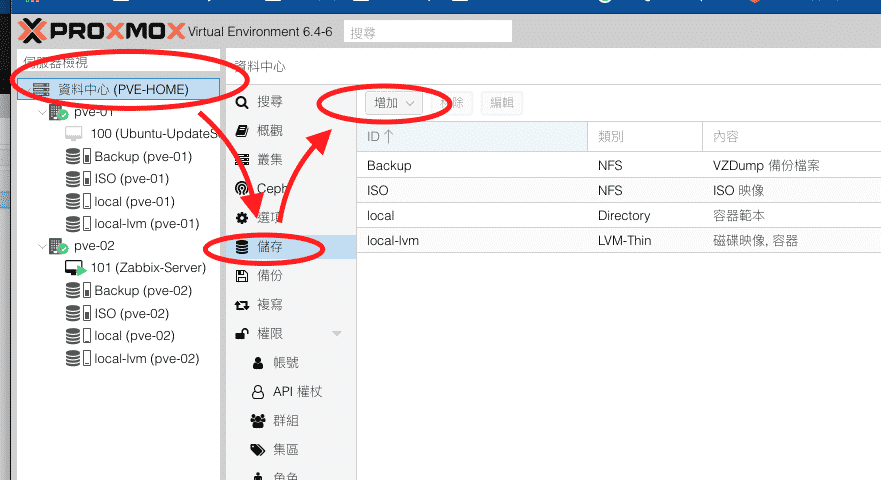
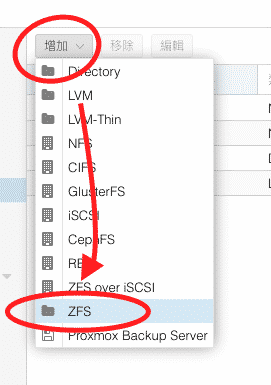
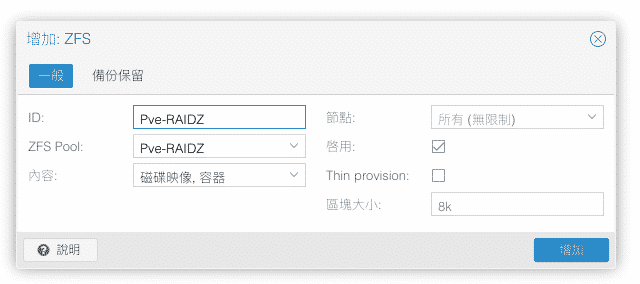
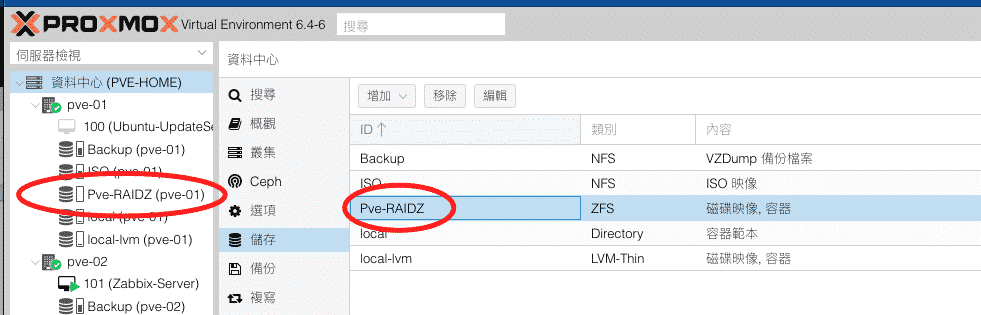
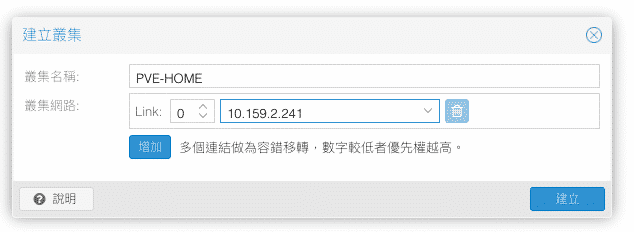
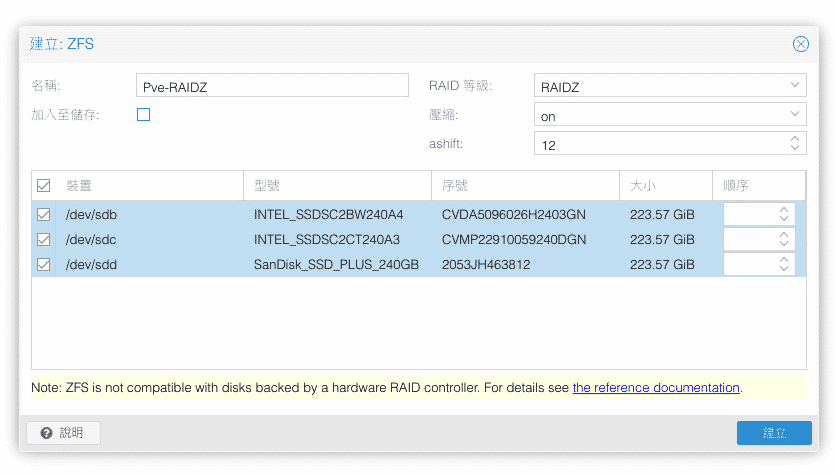 在一台新的Proxmox VE安裝好之後通常都會新增儲存區或者是現有儲存區新增硬碟
在一台新的Proxmox VE安裝好之後通常都會新增儲存區或者是現有儲存區新增硬碟